Background

Video Understanding은 꽤나 까다로운 task인게, 위 그림을 얼핏 보면 스케치하는 장면인거 같지만, 실제로는 공책 커버를 만드는 장면이라서, 각 frame에서 measuring, taping등 연관된 행동을 인식해서 연결했을떄만 제대로된 understanding이 가능해짐.
이런 video understanding을 풀기 위해 여러 vLLM들이 연구되어왔는데,
기존의 vLLMs는 짧은 비디오에 대해 학습되었고, 고정된 수의 프레임만 처리하도록 설계되었다. 긴 비디오에 적용시 다음과 같은 문제가 발생한다:
- 프레임 수가 많아져 Global Context를 이해하기 어려움
- 낮은 샘플링 비율은 세부적 정보를 손실시킴
- segment별 independent 처리 방식은 구간 간 관계를 파악하지 못함 --> 예를 들어 위 사진에서 measuring taping, 이런 작업들이 같은 작업의 일부라는걸 파악하지 못함.
이러한 한계를 극복하기 위해 Koala라는 새로운 접근법을 제안한 논문이다.
Proposed Approach: Koala
Key insight
Koala는 global context, local spatiotemporal information를 결합하여 긴 비디오의 구조적 정보를 이해한다.
- For Global context : 낮은 샘플링 비율로 키 프레임을 추출해 비디오의 전반적 흐름을 캡처한다.
- For Local spatiotemporal info : 높은 샘플링 비율로 세그먼트를 추출해 세부적인 정보를 보완한다.
새로운 tokenizer 구조
Koala는 두 가지 새로운 토크나이저 함수를 도입하여 시공간적 문맥을 이해한다:
- Conditioned Segment (CS): 세그먼트 내 프레임 정보를 통합하고 global context와 연결한다.
- Conditioned Video (CV): 세그먼트 간 관계를 추론하여 풍부한 시각적 토큰을 생성한다.
Overall Method
Koala는 짧은 비디오 처리에 특화된 vLLM을 기반으로 하며, 이를 긴 비디오에서도 작동할 수 있도록 확장한다. 먼저, 낮은 sampling 으로 주요 프레임을 추출해 비디오의 전반적인 global context를 파악한다. 그 다음, 높은 샘플링 속도로 추출한 non overlapping 프레임에서 세부적인 시간적·공간적 정보를 파악한다. 이걸 바탕으로 Conditioned Segment(CS)와 Conditioned Video(CV) 토크나이저를 사용해 soft visual token을 생성한다. CS는 세그먼트의 세부 정보를, CV는 주요 프레임의 global context와 CS의 정보를 결합해 비디오의 종합적인 정보를 담는다.
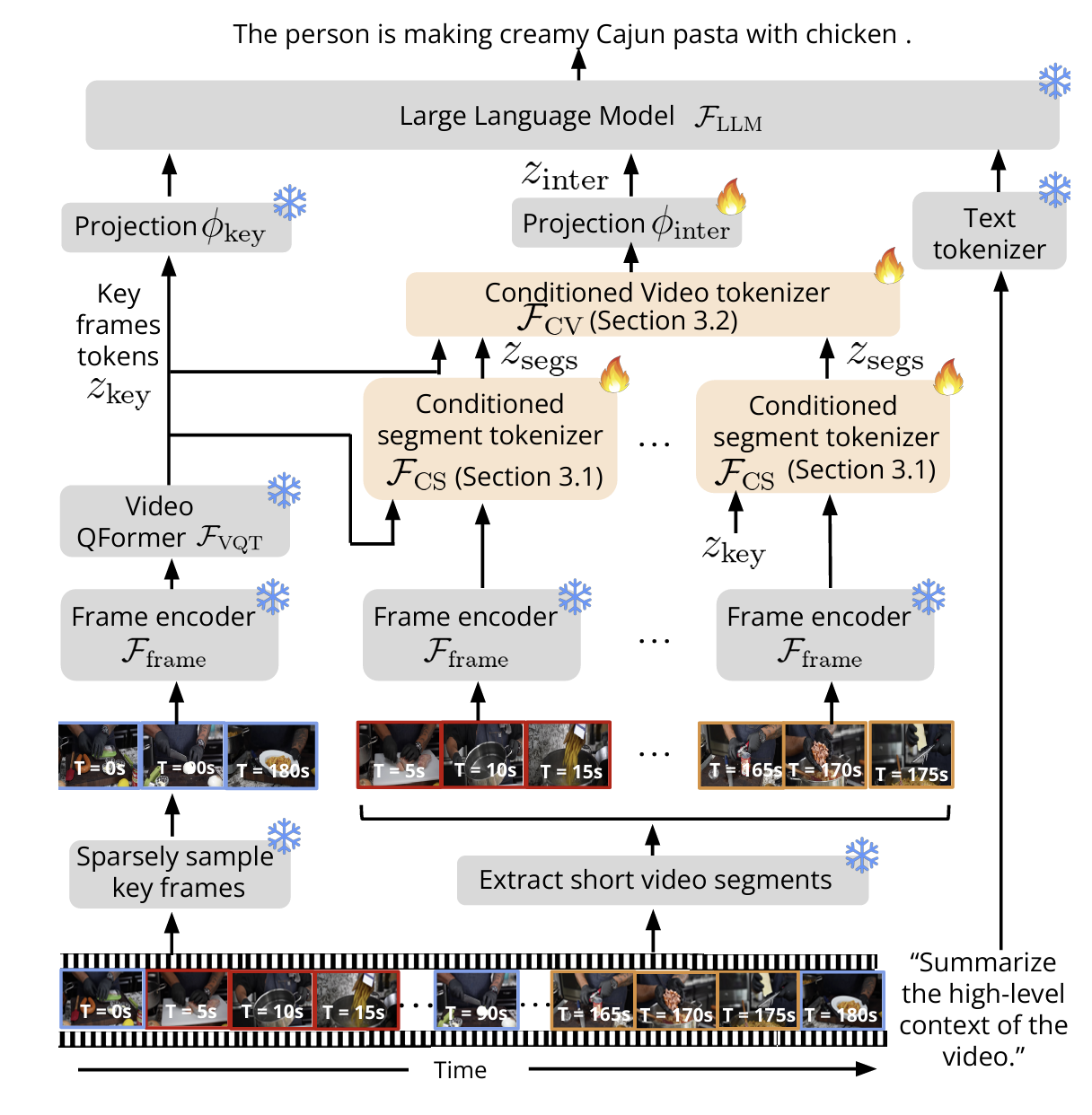
흐름1) 우선 직관적으로, 아주 simple 하게 생각해서, 텍스트 쿼리랑 + long video를 llm한테 넘겨주는데, long video를 input으로 받기 힘드니까, sampling rate를 아주 듬성듬성 key frame을 뽑아서 넘겨준다고 생각해보자.
Koala는 비디오 \( V \)에서 키 프레임 \( V_{\text{key}} \subset V \)를 추출한다. 키 프레임은 비디오의 주요 장면을 나타내며, 이를 통해 global context를 이해한다. 키 프레임은 아래의 토크나이저 함수로 처리된다:
$$ z_{\text{key}} = F_{\text{Key}}(V_{\text{key}}) = F_{\text{VQT}}(F_{\text{frame}}(V_{\text{key}}); Q_{\text{video}}) $$
키 프레임 토큰 \( z_{\text{key}} \)는 비디오의 global context를 나타내며, 이는 이후 텍스트 쿼리 \( z_{\text{text}} \) 랑 결합되어서 LLM에 인풋으로 넘어가서 최종 텍스트 r을 생성한다.
$$ r = F_{\text{LLM}}(\text{concat}\{z_{\text{text}}, \phi_{\text{key}}(z_{\text{key}})\}) $$
하지만 이 Key frame 을 추출해서 넘기는 접근법은 너무 coarse한 정보만을 반영하기에 정보손실이 많다는 문제가 있다.
흐름2) 그래서 추가적으로 비디오를 여러 segment로 나누어 각 세그먼트에서 세부적인 시공간 정보를 추출하고, 이를 통해 키 프레임 정보를 보완한다. 이 과정에서 global+ local context 모두 이해할 수 있게됨.
구체적으로는, 비디오 \( V \)를 \( N \)개의 겹치지 않는 세그먼트 \( S = \{S_1, S_2, \dots, S_N\} \)로 나눈다. 각 세그먼트 \( S_i \subset V \)는 higher frame rate로 샘플링된다. 이를 통해 얻어진 contextualized inter-segment tokens \(\phi_{\text{inter}}(z_{\text{inter}})\)은 다음과 같이 계산된다:
$$ r = F_{\text{LLM}}(\text{concat}\{z_{\text{text}}, \phi_{\text{key}}(z_{\text{key}}), \phi_{\text{inter}}(z_{\text{inter}})\}) $$
여기서 \(z_{\text{inter}}\) 는 논문에서 제시한 CS tokenizer이랑 CV tokenizder를 통해 계산이 된다. semgment level이랑 video level이랑 다르게 처리되는데, 간단하게만 먼저 살펴보자.
1. At the segment level (CS)
CS 토크나이저는 *(\( z_{\text{key}} \))에서 인코딩된 global contexxt를 조건으로 사용하여, 각 세그먼트 \( S_i \) 내에서 visual concepts를 식별한다. 기존 pretrained된 \( F_{\text{VQT}} \)는 프레임 세그먼트 내의 context만 통합하며, 세그먼트 간 관계는 처리하지 못한다.
2. At the video level (CV)
CV 토크나이저는 \( F_{\text{VQT}} \)를 기반으로, 서로 다른 세그먼트 간의 시공간적 context를 추론한다. 이를 통해, global context를 conditioning한 세그먼트 간 관계를 이해한다.
3. 최종 token ( (z_{\text{inter}}\) )
CS와 CV 토크나이저는 더해져서 최종적으로 contextual inter-segment tokens -> \( z_{\text{inter}} \)을 생성한다.
$$ z_{\text{inter}} = F_{\text{CV}} \left( \{ F_{\text{CS}} (S_i \mid z_{\text{key}}) \}_{i=1}^N \mid z_{\text{key}} \right) $$
그럼 CS tokenizer이랑 CV토크나이저가 어떻게 돌아가는지 하나씩 자세히 보자.
1. CS Tokenizer

첫번째 overall pipeline 그림의 Fcs 부분을 자세히 그려놓은 그림이다. global 토큰을 뽑을떄와 마찬가지로, Video Q former를 기반으로 하지만, 여기서 두가지 변경사항이 있다.
일단 segment 토크나이저는 global 토큰을 conditioning하면서, 각 segment의 토큰을 뽑아야한다. 그럼 conditioning하게 하려면 어떻게 할까?
기존 Qvideo(기존 Q former의 pretrained된 비디오 쿼리이다) 쿼리에, global context도 같이 넣어주면 된다. 그래서 아까 듬성듬성하게 뽑아서 Q former를 태워서 만들어진 Zkey가, Qvideo랑 같이 쿼리로 들어간다. 근데 이렇게만 들어가면 원래 pretrained Qformer에 잘 호환이 안되니까 , learnable한 쿼리 Qseg를 하나 더 만들어서 더해주는거다.
그럼 Cross Attention될떄, 쿼리에 따른 key value를 찾으니까, 원래 목표했떤 global 토큰을 컨디셔닝 하면서 segment의 토큰을 뽑을 수 있게된다.
여기서 출력으로는 쿼리 토큰 + segment 토큰 이 나오는데, 이 쿼리 토큰은 안쓰여서 그냥 discard해준다.
2. CV Tokenizer

그럼 CV Tokenizer를 보자.
아까 CS tokenizer는 global context에 따른, segment의 feature를 뽑아내려고 하는거라면, CV Tokenizer의 목적은, 이 segment끼리의 흐름을 파악하는거다. 맨 처음 예시에서 봤던거 처럼, 공책 커버를 만든다고 했을떄, measuring, taping, drawing 이런게 다 하나의 작업임을 인식하게 하는 과정인거 같다.
비슷하게, Qformer를 살짝 바꾼 구조인데
아까 Fcs에서 나온 segment토큰이 \(z_{\text{segs}, i}\) 이 cross attention되는 부분에 더해진다. 이떄, Video QFormer와 호환되도록 하기 위해, 학습 가능한, 시공간적 context를 조정하는 \(Q_{\text{temp}}\)를, 그리고 \(Q_{\text{concepts}}\) 라는 비디오 전체에서 공통된 개념적 관계를 통합하는 학습 가능한 쿼리를 도입한다.
최종적으로는 \(z_{\text{segs}, i}\), \(Q_{\text{temp}}\), \(Q_{\text{concepts}}\)를 결합하여 최종 세그먼트 토큰 \(Q_{\text{final}}\)을 생성한다:
$$ Q_{\text{final}, i, t} = z_{\text{segs}, i, t} + Q_{\text{temp}, i} + Q_{\text{concepts}, t} $$
그리고 CS 토크나이저랑 비슷하게, global context인 Zkey가 더해지는데, 이떄 learnable한 쿼리 Qinter를 하나 더 넣어준다.
$$ F_{\text{CV}}(z_{\text{segs}} \mid z_{\text{key}}) = z_{\text{key}} + w \cdot F_{\text{VQT}}(Q_{\text{final}}; \text{concat}\{Q_{\text{video}}, z_{\text{key}} + Q_{\text{inter}}\}) $$
Learning Objective
Koala의 최종 목표가 긴 비디오를 요약하고, 해당 비디오의 high-level task를 자연어 형식으로 설명하는 것이다. 이 모델을 학습시키기 위한 데이터 구성은 다음과 같다
- 비디오 (\(V\)): 입력 비디오.
- 질문 (\(P\)): 해당 비디오에 대한 prompt
- 응답 (\(R\)): 응답 텍스트로, 단어 시퀀스 \(R = \{\hat{l}_1, \hat{l}_2, \dots, \hat{l}_M\}\)로 표현되며, 각 단어는 원핫벡터로 표현된다.
학습은cross-entropy loss를 최소화하는 방식으로 이루어진다:
$$ \mathcal{L}(V, P, R) = -\sum_{j=1}^{M} \hat{l}_j \log p(l_j \mid \hat{l}_{<j}, V, P) $$
- \( \hat{l}_j \): \(j\)-번째 단어의 실제 값(one hot vector로 표현된)
- \( p(l_j \mid \hat{l}_{<j}, V, P) \): 비디오 \(V\), 질문 \(P\), binary 단어 \(\hat{l}_{<j}\)를 기반으로 \(j\)-번째 단어를 예측할 확률.
이 손실 함수는 모델이 주어진 비디오와 질문에 대해 응답 단어를 순차적으로 생성하도록 한다. 모델은 예측 단어와 실제 단어 간의 확률적 차이를 최소화하도록 학습한다.
Results

VQA task에서의 결과, 여러 벤치마크에 대한 다른 결과는 논문 참고..
Ablation 결과이다

아까 Zkey ( 각 cs이랑 cv에서 나왔던 query 토큰을 버린다고 했는데, 만약에 query 토큰을 살려서, 그걸 zkey 로 쓰면 성능이 확떨어지는걸 볼수 있다.
그리고 zkey를 conditioning하는(논문의 핵심 아이디어였던..) 것을 ablate 했을때랑 비교했을떄, 1프로 성능향상밖에 없어서 살짝 실망스럽긴 하지만, 1프로도 대단한거같긴하다.
이 논문의 아이디어랑 비슷한 실험을 해봤었던 적이 있는데, Ego centric long video에서 global feature를 뽑아서, 쿼리에 추가로 concat해봤던적이 있다. 이때 성능이 오히려 더 떨어져서, 그냥 덮어뒀었는데, 지금 이 논문 읽고 생각해보니까, global feature를 한개만 뽑아서 condtioning한것이 가장 큰 문제였던거 같다. 그리고 Ego centric 비디오의 특성상 문맥을 파악하기 되게 힘들다.1인칭 view이다보니까 사람한테 영상 보여주고 뭐하고 있는지 판단하라고 해도 흐름을 파악하기가 되게 어렵다. 이걸 쿼리에 concat해버렸으니 모델이 predict하기에 더 어렵게 만든것 같다.
이거는 Koala - attention heatmap 시각화한거

global하게 전체를 다 본다는게 되게 신기한거 같다.
