<Intro>
Limitations of 기존 LLM
기존 LLM은 텍스트 생성이나 이해에 뛰어난 성능을 보여주었지만, 멀티모달, 특히 비디오 이해(video understanding)에 있어서는 visual details나 temporal dynamics를 분석해야 하기 때문에 한계가 있었다. 비디오 이해를 잘 수행하기 위한 다양한 연구가 있었지만, 대부분은 비디오 캡션 생성 또는 핵심 주제 요약에 그쳤다. 기존 LLM은 세부적인 시간 경계(time boundary)와 같은 시간적 특성을 제대로 파악하지 못한다.
두 가지 main challenge
- 정확한 시간 경계를 갖춘 대규모 데이터셋의 부족.
- 비디오 내 여러 순간의 콘텐츠를 이해하도록 훈련할 수 있는 효과적인 시간 관련 비디오 작업(temporal-related video task) 설계의 어려움.
VTimeLLM
이러한 문제를 해결하기 위해 논문에서는 VTimeLLM이라는 모델을 제안한다. VTimeLLM은 비디오 내 세부적인 시간 경계(fine-grained segments)를 더 잘 이해하고 시간적 추론 능력(temporal reasoning ability)을 갖춘 모델이다.
VTimeLLM의 주요 component
- Visual Encoder & Visual Adapter: 입력 비디오를 처리.
- 맞춤형 LLM: 텍스트와 비디오 콘텐츠를 동시에 이해하도록 설계.
3 stage training strategy
- 1단계: 이미지-텍스트 정렬(image-text alignment): 대규모 이미지-텍스트 데이터를 활용해 시각적 특징과 LLM의 의미 공간을 align.
- 2단계: 시간 경계 인식 강화: 단일 및 다중 턴 QA 작업을 통해 시간 경계 인식과 이벤트 이해 능력을 강화.
- 3단계: 명령 조정(Instruction Tuning): 고품질 대화 데이터셋을 통해 VTimeLLM을 인간 의도에 align시키고 비디오 세그먼트의 시간 이해 능력을 향상.
<Method>

Architecture
VTimeLLM은 비디오 데이터를 처리하고 이해하기 위해 LLM에 Visual Encoder와 Visual Adapter 두 가지 추가 모듈을 포함한다. 이 모듈들은 비디오의 시각적 정보를 텍스트 임베딩 공간으로 변환하는 역할을 한다.
Visual Encoder
시각적 인코더는 CLIP ViT-L/14 모델의 frozen 버전을 활용하며, 비디오를 다음과 같은 형태로 처리한다:
- 비디오는 \(T\)개의 프레임으로 이루어진 sequence \(V \in \mathbb{R}^{T \times H \times W \times C}\)로 표현한다.
- 모든 프레임 중 \(N = 100\)개의 프레임을 균일하게 샘플링하여, \( \{ \tilde{V}_1, \tilde{V}_2, ..., \tilde{V}_N \} \)를 생성한다.
- 각각의 프레임 \(\tilde{V}_i\)는 CLIP의 ViT 인코더를 통해 개별적으로 처리된다: \[ \{ v_i^{cls}, v_i^1, v_i^2, ..., v_i^p \} = \text{ViT}(\tilde{V}_i), \, i = 1, 2, ..., N \] 여기서 \(v_i^{cls}\)는 global feature를 나타내고, \(p\)는 ViT에서 생성된 패치의 개수를 의미한다.
Visual Adapter
Visual Adapter는 각 프레임의 globalr feature \(v_i^{cls}\)를 입력으로 받아, \(f(\cdot)\)을 통해 LLM의 텍스트 임베딩 공간으로 \(z_i\)로 변환한다:
\[ z_i = f(v_i^{cls}), \, i = 1, 2, ..., N \]
변환된 모든 프레임의 결과는 다음과 같이 표현된다: \[ Z = \{ z_i \} \in \mathbb{R}^{N \times d} \] 여기서 \(d\)는 LLM의 hidden dimension
프레임 간 시간적 관계를 여기서 명시적으로 모델링하지 않는데, 이는 LLM이 입력된 시퀀스 데이터를 처리하고, 시간적 관계를 학습할 수 있기에 그렇다.
Input of LLM
VTimeLLM은 비디오와 텍스트 데이터를 동시에 처리할 수 있도록 특수 토큰 <video>를 사용하며, 텍스트와 비디오 feature를 결합하여 모델에 입력한다.
(1) special 토큰 <video> 사용
비디오 콘텐츠를 나타내기 위해 <video>라는 토큰을 문장에 삽입한다. 예를 들어:
"This is a video <video> can you describe this video?"
(2) 텍스트 임베딩 처리
<video>를 제외한 모든 단어는 LLM의 임베딩 레이어를 통해 변환되어, 텍스트 임베딩 리스트 [w1, w2, ..., wM]로 생성된다.
(3) 비디오 feature 끼워넣기
비디오 임베딩 시퀀스 Z는 <video> 토큰의 위치에 삽입되어 최종 입력 리스트가 생성된다.
input = [w1, ..., wj-1, Z, wj, ..., wM]
여기서:
- wj-1와 wj는
<video>토큰에 인접한 단어를 나타낸다. - 예를 들어, 위 예시 문장에서 wj-1는 "video", wj는 "can"에 해당한다.
그리고~
LLM은 이 결합된 입력 리스트를 받아 비디오 콘텐츠와 텍스트 쿼리를 동시에 처리한다.
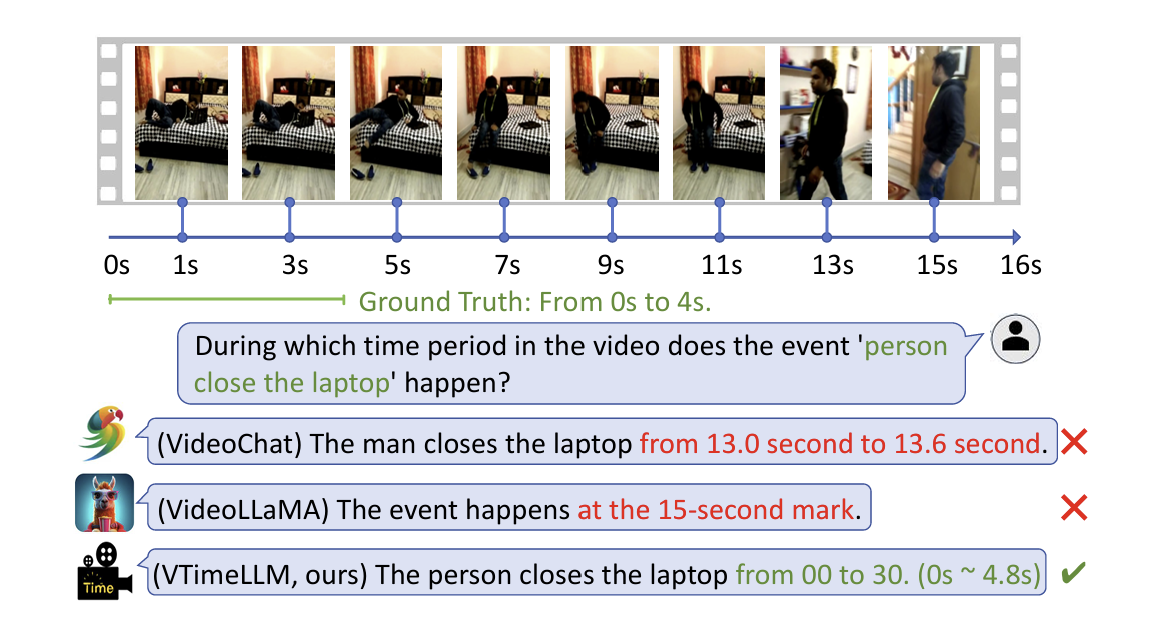
Output for Temporal Boundaries
VTimeLLM은 비디오의 Temporal Boundaries를 텍스트 형식으로 출력한다. -->이런식
"from s to e"
Boundary-aware Training
VTimeLLM은 기존 비디오 LLM의 2단계 학습 전략(feature alignmentf랑 instruction tuning)에 더해 시간적 이해 능력을 향상시키기 위한 추가적인 학습 단계를 도입한다. 이를 통해 모델이 비디오 내 세부적인 시간 경계를 잘 이해할 수 있도록 한다.
1단계 Feature Alignment
비디오 특징을 LLM의 의미적 공간(semantic space)과 정렬시키기 위해 이미지-텍스트 쌍 \(\langle I, T \rangle\) 데이터를 활용하여 Visual Adapter \(f(\cdot)\) 를 학습한다.
아래와 같이 생성된 이미지 임베딩을
\[ Z_I = f(\text{ViT}(I)^{cls}), \]
텍스트 임베딩 시퀀스 \([w_1, w_2, \cdots, w_M]\)를 결합하여 최종 입력 시퀀스를 구성한다:
\[ \text{input} = [Z_I, w_1, w_2, \cdots, w_M]. \]
생성된 입력 시퀀스를 LLM의 원래 auto-regressive training objective에 맞춰 비주얼 어댑터 \(f(\cdot)\)를 학습시키는 데 활용한다
데이터 구성은 다음과같다.
- 이미지-텍스트 쌍으로 이루어진 LCS-558K 데이터셋을 사용한다.
- 비디오-텍스트 데이터셋은 사용하지 않는데, 그 이유는 다음과 같다:
- 텍스트 노이즈 문제: 기존 비디오-텍스트 데이터셋(WebVid2M 등)은 텍스트에 많은 노이즈가 포함되어 있어 비주얼 특징과 텍스트 의미 간 align을 방해한다.
- 정보 손실 문제: 비디오를 텍스트로 요약할 때, 세부적인 (색상등)시각적 정보가 손실될 가능성이 크다. 반면, 이미지를 텍스트로 요약하면 손실이 상대적으로 적다
2단계 Boundary Perception
Boundary Perception 단계에서는 모델이 연속적인 이미지 프레임을 이해하고, 각 비디오 세그먼트의 의미를 파악하면서 시간 경계와의 align 강화하도록 학습한다.
데이터 구성
<기존 문제점>
- 대규모 데이터셋 부족: 비디오 세그먼트의 타임스탬프와 의미를 수작업으로 주석 처리하는 것은 시간이 많이 소요됨.
- 기존 방식의 한계: 자동 음성 인식(ASR) 기반 텍스트 전사와 비디오 세그먼트를 정렬하는 기존 방법은 다음 문제를 가짐:
- 행동과 음성간 alignment 부족.
- boundary annotation의 정확도가 낮음.
<해결책: InternVid-10M-FLT 데이터셋>
데이터 선정 기준
- 비디오 길이는 120초를 초과하지 않음.
- 비디오는 서로 겹치지 않는(non-overlapping) 이벤트 주석을 포함.
- 각 이벤트는 최소 3초 이상 지속되며, 평균 이벤트 길이는 비디오 길이의 8%를 초과.
--> 이렇게 총 134,000개의 비디오를 선정했으며, 각 비디오는 여러 이벤트와 그에 대한 대략적인 시간 주석 및 텍스트 설명을 포함한다.
<QA 대화 데이터 생성>
비디오 event 정보를 기반으로 LLM 학습에 적합한 QA(질문-응답) 대화 데이터를 생성한다.
QA 데이터 구조
- 각 비디오에는 이벤트 정보 \(\{s_i, e_i, T_i\}\)가 포함된다:
- \(s_i, e_i\): 이벤트의 시작 및 종료 시간(프레임 단위, 00~99).
- \(T_i\): 해당 이벤트의 텍스트 설명.
QA 대화 유형

1. Single-turn QA (단일 질문-응답)
- 작업: Dense Video Captioning.
- 질문(Q1): 비디오의 모든 이벤트와 해당 타임스탬프에 대한 포괄적인 설명 요청.
응답(A1): 각 이벤트의 설명과 타임스탬프를 특정 형식으로 출력.
2. Multi-turn QA (다중 질문-응답)
- Segment Captioning: 타임스탬프를 기반으로 설명 생성
- Temporal Video Grounding: 설명을 기반으로 타임스탬프 생성.
- 질문은 이벤트 순서에 상관없이 무작위로 제시되며, 각 이벤트에 대해 두 작업 중 하나를 요구.
- 10개의 질문 템플릿을 설계하여 QA 대화 데이터를 생성.
<Training Strategy>
1. 입력 format

- QA 데이터를 원래 LLM의 형식에 맞춰 포맷팅.
- 첫 질문 전에 "This is a video with 100 frames:
<video>\n" 문장을 추가.
생성된 QA 데이터를 활용하여 LLM의 auto-regressive training objective를 적용한다.
loss는 QA 응답 부분(A1, A2 등)의 토큰에만 계산한다.
LoRA (Low-Rank Adaptation): LLM을 미세 조정하기 위해 활용.
Visual Adapter: 동결(frozen) 상태로 유지하며 새롭게 추가된 LoRA 모듈만 학습.
3단계 Instruction tuning
Instruction Tuning 단계에서는 VTimeLLM이 비디오 내 모든 이벤트를 이해하고 해당 타임스탬프와 align하는 기존 능력을 기반으로, 더 정확한 비디오 시간 이해와 추론을 가능하게 한다. 또한, 사용자와 자연스럽게 대화할 수 있는 능력을 추가로 학습한다.
이 단계는 다음과 같은 문제를 해결하기 위해 설계었음.
- 출력 오버피팅 문제: 2단계 학습 결과, 모델이 단순한 응답("from 00 to 10")만 제공하며 대화 능력이 부족함.
- 노이즈 데이터 문제: 2단계에서 사용된 InternVid 데이터셋의 자동 주석이 정확하지 않고, 노이즈가 포함됨.
데이터 구성
high quality QA 데이터셋( ActivityNet Captions와 DiDeMo 에서 일부 비디오 선택)
QA 대화 데이터 변환
각 비디오의 이벤트 정보 \(\{s_i, e_i, T_i\}\)를 기반으로 QA 대화 데이터를 생성한다.
이전 단계에서 사용된 템플릿 기반 대화는 모델 오버피팅 문제가 있었기에 이 단계에서는 템플릿 대신 LLM을 활용한다:
Training
LoRA module
- 2단계에서 학습된 LoRA 모듈을 원래 모델과 병합.
- 새로운 LoRA 모듈을 추가하여 이 단계에서 학습 가능한 유일한 param
- 나머지 모든 파라미터는 freeze
Result

Ablation
