INTRO + ABSTRACT
OMG-LLaVA라는 픽셀수준의 understanding과 reasoning을 결합한 새로운 프레임워크를 제안한 논문이다.
MLLM(멀티모달 LLM)의 역사를 보면 아래와 같은데

(a)는 LLM에 visual token을 도입해 LLM이 visual information을 이해하고 이에 기반한 reasoning 과 추론을 가능하게 한 LLaVA같은 모델이다. 이 모델의 한계점은 object level 이나 pixel level의 세밀한 작업은 수행할 수 없다는 단점이 있다.
(b)는 여기에 Region Feature Extractor을 추가로 달아서 object level의 작업까지는 가능해졌는데 여전히 pixel level의 작업은 수행할 수가 없다
(c)는 segemntation token 이 추가로 도입되어 pixel-level understanding and reasoning tasks 도 수행할 수 있게 되었지만 복잡도가 큼. SAM과 같은 큰 segemnetation module이 필요하다는 단점.
(d)는 GLAMM모델인데, (c)의 파이프라인을 결합해 object level 이랑 pixel level 이 한번에 처리되었지만 복잡성이 역시 너무 크고, instance segemntation이나 panoptic segmentation등 pixel-level의 tasks하는 능력을 잃어버림.
(e)는 OMG-LLaVA의 모델로 image level, object level, pixel level의 visual understanding and reasonintg task를 하나의 framework로 합친 첫번째 시도라는 점에서 novelty가 있음.
METHOD
이렇게 다양한 task를 토큰 생성 작업으로 모델링하여 이미지 수준, 객체 수준, 픽셀 수준 이해 및 추론 간의 격차를 줄임. 이를 지원하기 위해 세 가지 유형의 토큰을 다음과 같이 정의함.
- text token \(T_t\)
- pixel centric visual tokens \(T_{pv}\)
- object centric visual tokens \(T_{ov}\)
text token은 텍스트 정보를 인코딩하고, pixel centric visual tokens는 dense 한 feature로 LLM에 전체적인 이미지 정보를 제공하고, object centric visual tokens는 지정된 object의 feature를 인코딩하여 LLM에 object centric 정보를 전달하고 쉽게 세분화 마스크로 디코딩될 수 있음
이 모든 작업은 다음과 같이 통합될 수 있음
\[ T_{t}^{out}, T_{ov}^{out} = LLM(T_{pv}^{in}, T_{ov}^{in}, T_{t}^{in}) \]
예를 들어, image caption과 같은 고전적인 image leve understanding task에서는 텍스트 응답 \( T_{t}^{out} \)이 텍스트 지시 \( T_{t}^{in} \)와 이미지 특징 \( T_{pv}^{in} \)에 기반하여 생성됨. object level understanding 작업에서는 텍스트 응답 \( T_{t}^{out} \)이 텍스트 지시 \( T_{t}^{in} \), 이미지 특징 \( T_{pv}^{in} \), 그리고 object centric visual token \( T_{ov}^{in} \)에 기반하여 생성됨. Pixel lever reasoning task에서는 object centric visual token \( T_{ov}^{out} \)이 텍스트 지시 \( T_{t}^{in} \)과 이미지 특징 \( T_{pv}^{in} \)에 기반하여 생성됨
픽셀 중심 시각 토큰은 CLIP 백본을 사용하여 이미지를 토큰화하여 얻을 수 있지만, object centric visual token은 객체 정보를 인코딩하여 세분화 마스크로 쉽게 디코딩될 수 있어야 함. 따라서, Osprey의 마스크 풀링이나 GLaMM의 ROI 풀링과 같은 방법은 이러한 요구를 충족하지 못함으로 쓸 수 없음.
대신 이 논문에서 제시한 universal perception decoder로 이 모든 요구를 충족할 수 있으며, OMG-Seg 디코더를 object centric visual token을 선택했음.
OMG-LLaVA Framework
OMG-LLaVA 프레임워크는 크게 두 가지 주요 구성 요소로 나뉜다 (LLM과 frozen universal perception module)
1. LLM:
LLM은 텍스트 지시 토큰과 pixel centric 및 object centric 토큰을 입력으로 받아들이고, 이를 기반으로 텍스트 응답과 object centric token을 출력함. 즉, LLM은 사용자의 텍스트 명령을 이해하고 이에 따라 시각 정보와 결합하여 적절한 응답을 생성함.
2. Universal perception module:
이 모듈은 이미지를 인코딩하고 사용자로부터 받은 시각적 프롬프트를 pixel centric, object centric token으로 변환함. 이 모듈은 학습되지 않음.
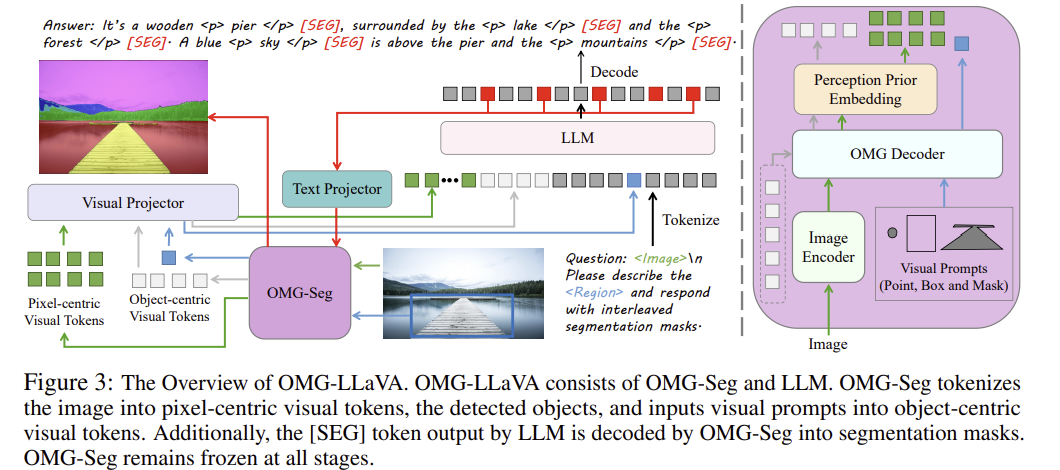
작동 방식
1. 이미지와 시각적 프롬프트 인코딩:
Universal perception module 은 이미지와 visual prompt를 받아 이를 pixel centric, object centric token으로 변환함. 이 변환된 토큰들은 visual projector 를 통과해서, 이미지의 세부 정보를 LLM에 전달함.
2. segmenatation mask생성:
LLM은 범용 인식 모듈로부터 입력받은 시각 토큰들을 사용하여 object centric 토큰을 출력함. 이 object centric token은 segementation mask response로 변환됨.
3. 텍스트와 시각 토큰 통합:
LLM은 텍스트 지시 토큰, pixel centric , object centric 토큰을 입력으로 받아들이며, 이를 기반으로 텍스트 응답을 생성함. 이 과정에서 시각 토큰들은 이미지의 세부 정보와 객체 정보를 포함하고 있어, 더 정확하고 상세한 응답을 생성할 수 있음
Model Architecture
Universal Perception module 세부 구조 (보라색 모듈 부분)
그림에서 볼 수 있듯이 Image Encoder, OMG Decoder, 그리고 Perception Prior Embedding으로 구성되어 있다. 그럼 하나씩 살펴보자
1. Image Encoder
이미지를 입력으로 받아서 Decoder 에 넘겨줄 token이 생성됨. 논문에서는 ConvNeXt-L 기반의 CLIP모델이 인코더로 사용되었고, 1024x1024 이미지가 입력으로 256 개의 토큰이 출력으로 나옴.
입력 (1024x1024 이미지) -> 32배 다운샘플링 (32x32) -> Pixel shuffle operator -> (16x16) = 총 256개의 visual token이 생성됨.
2. OMG Decoder:
object-centric visual tokens을 생성하여 LLM에 이미지의 주요 object 와 사용자가 입력한 visual prompt로 언급된 object 에 대한 정보를 제공하는 친구
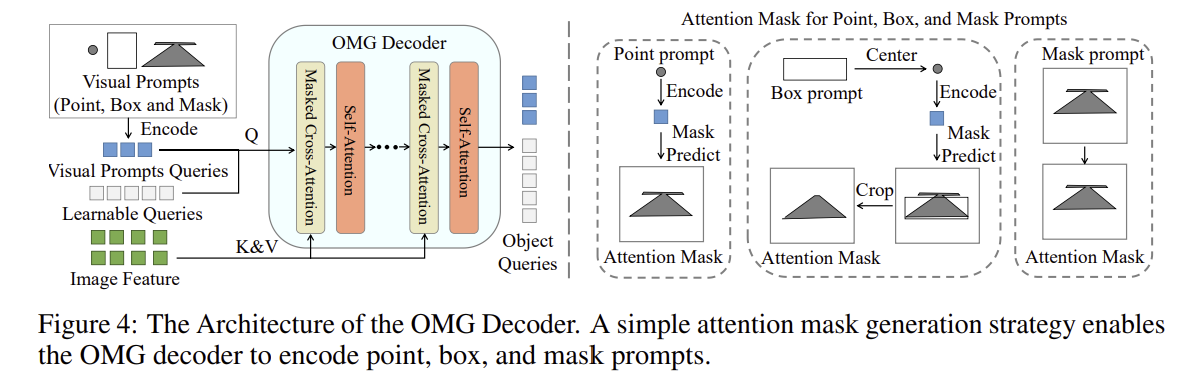
구성요소
1. Masked Cross Attention & Self attention layer
Masked cross attention이랑 Self attention layer 로 구성되어 있으며, Masked cross attention은 이미지 feature 에서 object 쿼리를 탐색하고, self attention은 object 간의 관계를 탐색하는데 쓰임.
2. Learnable Object Queries
이미지에서 관심 object를 캡처하고, visual prompt와 함께 object 쿼리로 사용됨.
3. Decoding
FFN 레이어를 통해 segmentation mask와 object category로 디코딩 될 수 있음.
정리해보자면 OMG 디코더에는 Q 쿼리로 visual prompt와 learnable object queries, 그리고 키와 벨류 K, V 에는 Image Encoder 에서 나온 image feature 들이 들어가서 corss attention이랑 self attention이 되는 형태.
그럼 Visual Prompt 가 어떻게 들어가야하는지 궁금할텐데,
Main Figure 에서 볼 수 있듯이 visual prompt에는 point, box, mask를 처리할 수 있음.
근데 OMG Decoder 에 들어가는 input 은 point prompt형태여야함. Point visual prompt의 경우 그냥 넘겨주면 되고, box랑 mask는 point prompt 로 변환하고 넘겨주면 됨.
그치만! 이 과정에서 문제가 생겨버림. 바로.. 박스랑 마스크를 point prompt로 변환해주면 정보가 너무 많이 손실됨.
그래서 논문에서 제안한거는, visual prompt 를 기반으로 masked cross attention layer 의 attention mask에 constriant 를 줘서 사용자의 의도를 정확히 인코딩하고자 함.
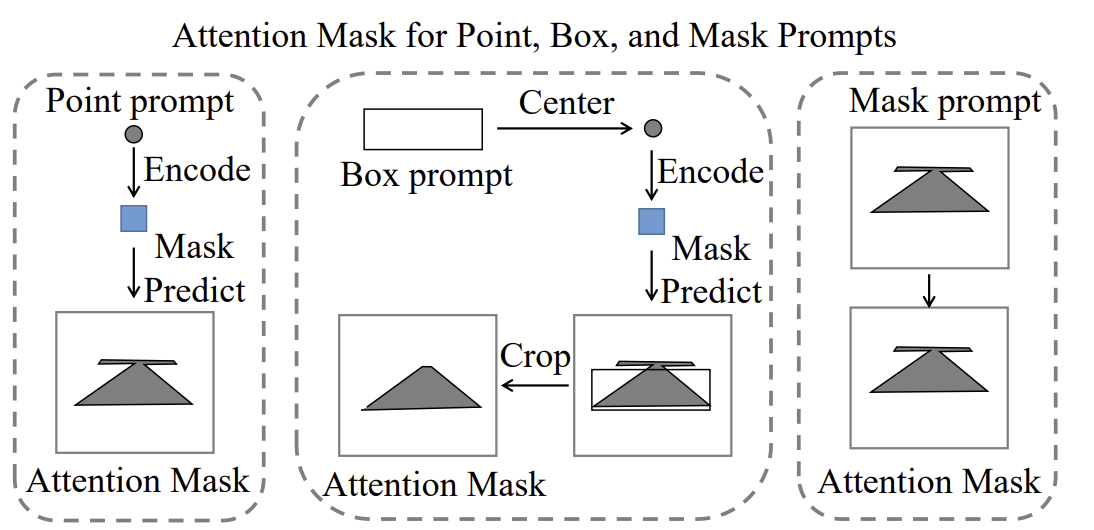
박스 prompt 의 경우에는 박스 좌표를 사용해서 박스 외부의 모든 pixel feature 에 대해 attention mask를 씌우고
Mask prompt의 경우 object mask를 사용해서 attention mask를 씌우는거.
이부분이 잘 이해가 안갈 수도 있는데,
예를 들어 박스 프롬프트의 경우, 사용자가 입력한 bbox가 이미지의 왼쪽에 있다고 가정하면, attention maks는 이 박스 외부의 모든 영역을 무시하도록 설정해(박스 외부의 모든 픽셀에 대해 attention을 0으로 설정하는거지). 그러면 attention은 박스 내부의 pixel 에 대해서만 주의를 기울이게 됨.
Mask prompt의 경우에도 사용자가 입력한 마스크가 예를 들어 '고양아' 라고 하면, attention mask는 고양이 외부의 모든 영역이 무시되도록 설정이 됨.
3. Perception Prior Embedding
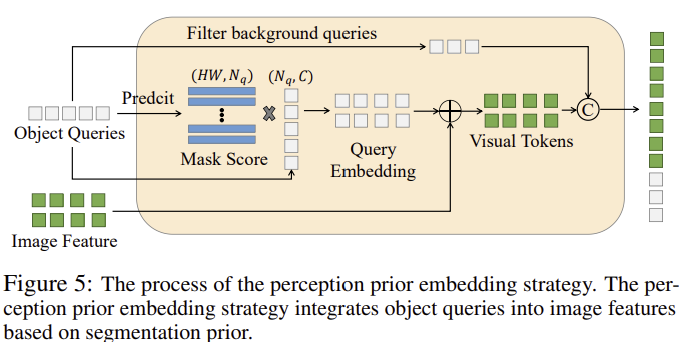
Perception Prior Embedding은 image feature이랑 query를 효과적으로 통합하여 object centric token을 생성함. 이를 통해 LLM이 더 정확한 reasoning 과 추론이 가능해짐.
작동 방식
1. 이미지 특징과 객체 쿼리의 결합:
이미지 인코더는 image feature \( F \)를 생성하고, OMG 디코더는 object 쿼리 \( Q \)를 생성한다. 이 두 가지 정보를 결합하여 pixel centric token \( T_{pv} \)이 생성됨.
2. Object 쿼리의 가중 평균 계산:
object 쿼리 \( Q \)는 segmenatation mask \( M \)와 score \( S \)를 사용하여 계산됨. segmenation mask \( M \)와 score \( S \)를 기반으로 마스크 점수 \( MS \)를 계산함.
여기서, \( M \odot S \)는 segmentation mask와 score의 곱셈
3. Object Centric toekn 생성:
마스크 점수 \( MS \)를 사용하여 object 쿼리 \( Q \)의 weighted average를 계산함. 이를 통해 생성된 객체 중심 시각 토큰은 다음과 같음
여기서, \( MS \cdot Q \)는 object 쿼리의 weighted average이며, 이를 이미지 특징 \( F \)에 더하여 최종 픽셀 중심 시각 토큰 \( T_{pv} \)를 생성함.
4. Object centric 토큰과 Pixel Centric 토큰의 결합:
생성된 pixel centric 토큰 \( T_{pv} \)와 object centric 토큰 \( T_{ov} \)을 통합하여 최종 토큰 \( T_v \) 이 형성됨:
이걸 LLM에 넘기는것임.
Visual Projector
Visual token 을 LLM의 text embedding 공간으로 mapping 해주는 역할을 함. Input으로는 (OMG-Seg (위에서 본 보라색 모듈)) 에서 나온 object centric visual token 이랑 pixel centric visual token을 각각 MLP (총 2개)에 태워서 text embedding 공간으로 mapping 해줌
Text Projector
LLM 출력의 hidden state 를 시각적 공간으로 mapping. 주로 segmentation 토큰의 hidden state를 시각적 공간으로 mapping 해서 segemnation mask 생성.
Training and Testing Setup
Training
두가지 스텝: pretraining and instruction tuning으로 나뉜다.
Pretraining stage에서는 perception model이랑 LLM 은 frozen 되어 있고, visual and text projectors 만 학습이 가능하다. Text regression loss에 대해서는 visual projector \(P_v\) and text projector \(P_t\) 가 object-centric information을 최대한 잘 보존하도록 regularization penalies 가 적용된다.
Pretraining loss:
Instruction tuning 단계에서는 visual projector이랑 text projector를 파인튜닝하는거에 추가로 LLM을 파인튜닝하기 위해 LoRA가 사용된다. Text regression loss뿐만 아니라 [seg]토큰에 의해 decoding 된 segmentation mask를 supervise 하기 위해 cross-entropy loss(픽셀간 정확도)랑 dice loss(seg mask 의 전반적 형태 구조, 전체적인 유사성 높이기 위해)도 사용되었음.
Instruction tuning loss:
Testing
Inference 단계에서는 text prompt, visual prompt, image feature 이 토큰으로 인코딩되어 LLM에 입력으로 들어가고, LLM의 출력 토큰은 task response 랑 seg mask response로 decoding 되어짐.
사실 모델 파이프라인 그림이 잘 그려있긴 하지만, 모델자체가 복잡한 편이라, 각 모듈의 입력과 출력에 대해 명확히 정리해보려고 한다
1. 이미지(1024x1024) 가 이미지 인코더를 통과하면 다운샘플링 된 이미지 feature F(16x16xc)가 출력됨.
2. 이미지 인코더에서 나온 이미지 feature F(16x16xC)와 object 쿼리 Q(Nq xC), visual prompt 쿼리 가 OMG 디코더에 입력으로 들어가면 object centred toke Tov, object 쿼리로부터 추출된 segmentation mask M(Nq X H X W) , 그리고 신뢰도 점수 S(1xNq) 가 출력됨.
3. 이미지 encoder 에서 나온 image feature F, OMG 디코더에서 나온 object 쿼리 Q, segementation mask M이랑 신뢰도 점수 S가 입력으로 들어가서
- 마스크 점수 MS 계산: MS=Softmax(M⊙S,dim=−1)
- wieghted object 쿼리 계산: Tpv=MS⋅Q+F
이 과정을 거치면 출력으로 pixel centric 토큰 Tpv(16 x 16 xC), object centered 토큰 Tov(NqxC) 가 나옴.
파란색이 입력, 빨간색이 출력
Result

Unified 모델임에도 각각의 task에 대한 SOTA모델이랑 비교할만한 성능을 가짐.
개인적으로 생각해본 Discussion point?
Training이 두 과정으로 나눠지면서 end to end 학습이 안되는거 같은데, 이미지 encoder , omg 디코더, LLM이 다 독립적으로 동작하는거 같아서 이부분에서 개선해 볼 수 있지 않을까..?
그리고 Perception prior embedding 을 할 때 object 쿼리랑 이미지 feature 이 결합되어 pixel centrered token이 만들어지는데, 이러면 global 한 특징을 잃어버릴 것 같아서
VIT 같은 백본에서 global 특징을 뽑아 object 쿼리랑 합치거나
이미지 encoder 의 마지막 레이어에 global average pooling 을 하나 더 쌓아서 global 한 특징을 추가로 object 쿼리랑 결합을 해보거나
등 조금더 global feature 를 추가시킬 방법은 없을지?