1. 기존 Generative model(stable diffusion 등등)의 한계
기존 Stable Diffusion과 같은 text-image 모델은 다양한 언어 prompt를 통해 이미지 생성하는데는 아주 뛰어나지만, 특정 공간적이거나 구조적인 control 하는게 어려움. Stable diffusion 뿐만 아니라 현재 이미지 generative 모델은 여러 조건을 하나의 통합된 모델에서 처리하는데 어려움을 겪고 있음.
2. ControlNet의 한계
최근 나온 ControlNet에서는 visual condition을 추가할 수 있게 되었지만, ControlNet은 하나의 modality에 대한 조건만 받아들일 수 있다는 한계점이 있음(edge map 같은 condition).
따라서, 이 논문에서 제안하는 모델은 UniControl로, 제어 가능한 조건(language and visual condition을 모두 handle) -> 이미지를 만드는 것을 하나의 프레임워크로 통합하면서, 다양한 임의의 프롬프트까지 줄 수 있는 모델.
3. Training Setup
이전의 stable diffusion 또는 ControlNet 과 같은 생성 모델과 달리, 시각 condition이랑 텍스트 condition을 동시에 받아야하니까, 이걸 하기 위해 학습 condition이랑 target을 pair 시켜 데이터셋을 구성함.
K개의 task로 구성된 데이터셋이 있다고 가정하면
D := {D1 ∪ · · · ∪ DK}
각 task training set Dk에 대해, 학습 쌍을 ([ctext, ctask], Ic, x)로 나타내는것.
(여기서 ctask는 task 유형, ctext는 target 이미지를 설명하는 language prompt, Ic는 image condtition, x는 타겟 이미지)
예시를 보자

여기서 task 는 Canny Edge 를 따라서 image를 생성하는것.
아까 만들어놓은 학습쌍
( [ctask, ctext], Ic, x)를 사용하여 task 별 학습 손실을 LDM 공식에 다음과 같이 적용시킬 수 었음.
$$ \ell_k(\theta) := \mathbb{E}_{z,\epsilon,t,c_{\text{task}},c_{\text{text}},I_c} \left[ \| \epsilon - \epsilon_{\theta}(z_t, t, c_{\text{task}}, c_{\text{text}}, I_c) \|_2^2 \right] $$
, $$ ([c_{\text{task}}, c_{\text{text}}], I_c, x) \sim D_k $$
여기서 t는 시간 단계를 나타내고, \( z_t \)는 시간 단계 t에서 노이즈가 추가된 latent tensor이며, \( z_0 = E(x) \)이고, \( \theta \)는 UniControl의 learnable parameter.
먼저 무작위로 과제 k를 선택하고 Dk에서 미니 매치를 샘플링하여 계산된 손실 \( \ell_k(\theta) \)로 \( \theta \)를 최적화하는 방식으로 학습이 이루어짐.
4. Model Design
가장 중요한 Model Design을 보자~
UniControl은 두가지 property를 만족하기 위해 설계 되었는데,
1) The model can overcome misalighnment of low-level features from different tasks
2) THe model can learn meta-knowledge across tasks, and adapt to each task effectively
즉, Unicontrol 은 각각의 task의 필수적이고 unique 한 정보를 각가 알 수 있어야하고 ( 즉 condition으로segementation map이 들어갔으면 아웃풋도 segmentation 관련된거, 3d 정보를 포함해서는 안됨. 각 task 별로 뚜렷한 정보를 가지고 있어야함)
그리고! 모델은 서로 다른 task 들의 차이점이나 유사성을 알 수 있어야함.(뒤에 나오겠지만 zero shot learning 같은것을 해서 안 본 task에 대해서도 학습을 시키려면 각각 task들의 differences를 모델이 명확하게 알고 있어야함.)
그러기 위해 두가지 novel 한 module 이 소개되었음.(MOE-Style Adapter, task-aware HyperNet)

MOE-Style Adapter

간단하게 얘기하자면,
다양한 image condition에서 low feature를 학습하여 UniControl이 adpative 하게 각 task의 unique 한 특징을 캡처할 수 있도록 하는 것.
여기서 사용된 아이디어는 LLM에서 쓰이는 Mixture-of -Experts 의 아이디어가 적용되는데
MOE
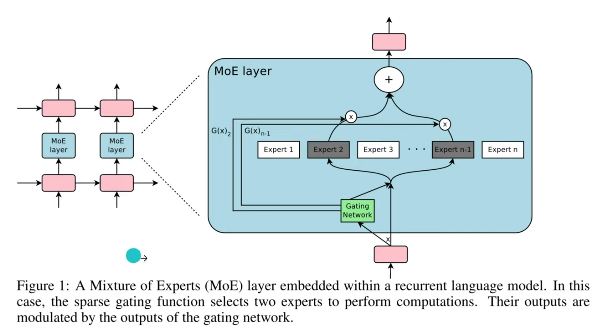
$$ y = \sum_{i=1}^{n} \mathbf{1}(g(x) = i) \cdot f_i(x) $$
- \( g(x) \)는 입력 \( x \)에 대한 expert의 선택을 결정하는 함수
- \( f_i(x) \)는 \( i \)-번째 expert 의 출력
즉 여러 expert에 대한 의견을 gate를 통해 통과시켜 각각 다른 가중치를 곱해 합치는 느낌. (g(x)의 합은 1)
여기서는 g도 학습가능한 함수
그럼 여기서 뭐가 바뀌었을까?
MOE-Style Adapter
$$ F_{\text{Adapter}}(I^k_c) := \sum_{i=1}^{K} \mathbf{1}(i == k) \cdot F^{(i)}_{\text{Cov1}} \circ F^{(i)}_{\text{Cov2}}(I^k_c) $$
여기서,
- \( \mathbf{1}(\cdot) \)은 인디케이터 함수
- \( I^k_c \)는 task \( k \)의 condition 이미지
- \( F^{(i)}_{\text{Cov1}}, F^{(i)}_{\text{Cov2}} \)는 어댑터의 \( i \)-번째 모듈의 컨볼루션 레이어
원래 MOE랑 비교했을떄 gate 함수가, 단순 1(i==k)로 바뀌었음을 알 수 있음. 즉 현재 task가 K에 해당하면 가중치가 1, 아니라면 가중치가 0인걸로 해버림.
이렇게 하면 task 별로 명확하게 구분이 되고, 추가적으로 parameter수도 확 줄어서 efficient 함.
(실제로 conventional 한 MOE로 했을떄 모델이 task 를 명확히 구분하지 못했다고 함. 아마 컨디션이 gate 통해서 weight를 곱하는 형태면 다른 컨디션들끼리 합쳐져서 그런것 같음)
Task-Aware HyperNet
Task-Aware HyperNet은 Controlnet 에서 제시된 zero-convolution module 을 변형한것으로,
Controlnet 의 zero-convolution module 을 먼저 보자
Controlnet 의 zero-convoluion module
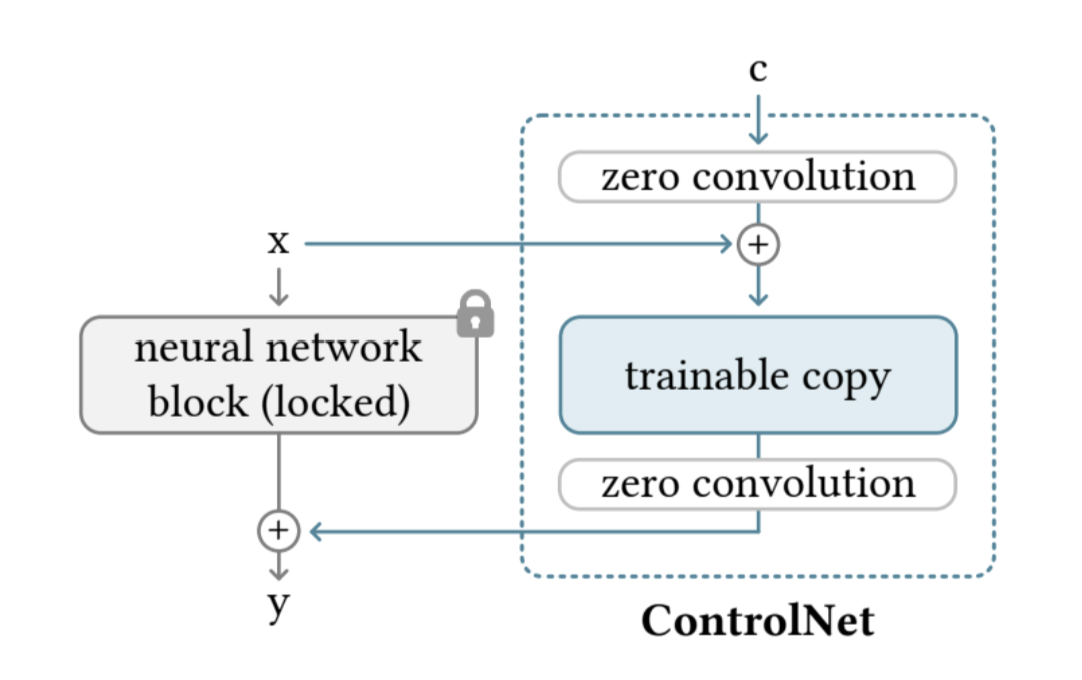
뭔가 resnet 이랑 느낌이 미슷한듯?
x라는 입력을 뉴럴 네트워크에 학습한거를 lock하고 copy를 하나 해버림. 그 copy한거에 컨디션을 추가하는 것. 구체적으로는 C(condition)을 zero convolution을 통과시켜 x랑 합쳐준거를 복사한 neural network에 통과 시키고, 다시 zero convolution을 해서 , y 아웃풋 전에 더해주는 것.
이렇게 하면 기존 feature 도 잘 보존되고, 동시에 conditioning 도 할 수 있게 됨.
그럼 다시 UniControl Model 을 보자!

MOE Adapter 에서 나온 feature map이 visual condition이 되어서 zero conv 를 통과.
Task Aware Hypernet은 task instruction을 처리하는데, 다음과 같이 task instruction이 들어가면 CLIP을 통해 encoding 시키고 여러 linear layer 를 거쳐서 Task embedding을 만들어줌.

이렇게 해서 만들어진 Task Embedding은 다음과 같이 zero convolution의 weight에 곱해지는 형태로 들어감.

이렇게 최종 zero conv 에서 나온 애는 Decoder 로 넘어가서 이미지를 생성하게 되는 원리.
5. Task Generalization Ability
Hybrid Tasks Generalization

인풋으로 두가지 condition을 넣으면, 예를들어 background, foreground가 들어가면 이거를 다시 hybrid task instruction으로 rewrite 되어, segementation map and human skeleton to image 로 합쳐짐.
Zero-Shot New tasks Generalization

처음 보는 visual condition에 대해서도, MOE style adapter 이 task wieght 를 적당하게 선형조합해서, 새로운 visual condition에 대해서도 generate 할 수 있게 됨.
zero shot 이 되는 이유가,
pretrained 된 작업이랑 새로운 작업 간의 공통 속성과 암묵적인 상관관계를 모델이 잘 이해하고 활용했기 때문인것 같음
예를 들어, colorize 작업에서는 모델이 세그멘테이션과 depth estimation 작업에서 얻은 이미지 구조에 대한 이해를 활용했고, 블러 제거와 인페인팅 작업에서는 엣지 detect및 outpainting 를 잘 조함해서 활용했음.