Intro
데이터셋이 너무 큰 경우 학습 비용이 너무 많이 든다. 그래서 좋은 데이터만 어떻게 잘 뽑아 쓸까, 에 대한 연구이다.
핵심 아이디어는 작은 vlm 을 사용해서, 어떤 데이터가 유용할지 골라낸다. 작은 모델의 내부 representation을 이용해서 training 데이터를 클러스터링을 한다. 그래서 데이터 속에서 concept - skill composition을 파악한다. (street sign/OCR) 이런식으로 어떤 컨셉인지, 그리고 이걸 답하기 위해서는 어떤 skill 이 필요한지 이런식으로 조합하는 느낌인거같다. 이렇게 하면 다양한 데이터를 소량만 뽑아도 성능 유지가 가능하다. 그래서 concept-skill composition으로 클러스터링을 해놓고, 각 클러스터에서 density와 transferability 를 기준으로 샘플링을 한다. 여기서 density는 얼마난 대표적인 데이터인지? Transferability 는 다른 concept-skill 클러스터쪽에도 도움이 되는 정보인지?
LLaVA 1.5 데이터셋에서, 전체 20프로만 사용해도 full 데이터 학습과 비슷한 성능을 냈다고 한다.
Method
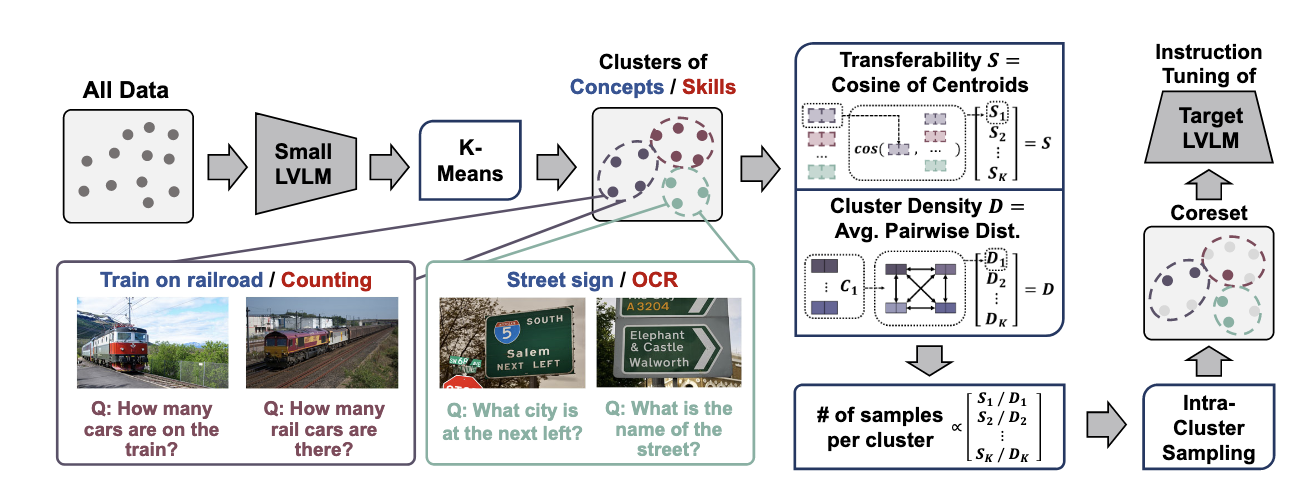
COINCIDE는 크게 다섯 단계로 요약된다.
- Representation 만들기 - 작은 LVLM의 여러 층 MSA 출력을 모아 tanh, mean-pool, L2 정규화를 거친다.
- 클러스터링 - 이렇게 얻은 벡터들을 spherical k-means로 크게 묶어 mode를 찾는다.
- 유사도 계산 - 각 클러스터의 transferability proxy(다른 클러스터와의 평균 코사인)와 density(군집 내부 유사도)를 구한다.
- 비중 배분- transferability는 높고 density는 낮은 cluster에 더 많은 할당량을 준다.
- 대표 샘플 고르기 - 각 cluster 안에서는 MMD greedy로 원래 분포를 가장 잘 대표하는 샘플을 뽑는다.
Transformer의 각 층은 다른 특징을 잡아낸다. 낮은 층은 색·모양 같은 저수준 패턴에, 중간 층은 객체나 관계에, 높은 층은 의미와 추론에 더 민감하다. 그래서 COINCIDE는 여러 층의 출력을 모두 모아, 한 샘플의 “개념–기술 조합”을 폭넓게 담아낸다.
Concept–Skill 조합 찾기
각 층의 출력은 극단값을 줄이기 위해 tanh를 거치고, 토큰 단위 값을 평균(pooling)해 하나의 벡터로 요약한다. 마지막으로 L2 정규화해 길이를 맞춘다. 이렇게 만든 벡터들을 합치면 샘플마다 하나의 긴 멀티모달 벡터가 생긴다.
이 벡터들을 spherical k-means로 클러스터링하면, 자연스럽게 “도로 표지판+OCR” 같은 mode 단위로 데이터가 나뉜다. K를 크게 잡는 이유는 한 군집이 하나의 mode만 담게 해서 mode purity를 높이기 위함이다.
Transferability proxy
transferability란 “이 클러스터에서 배운 게 다른 클러스터 학습에도 도움이 되느냐”이다. 실제로는 클러스터마다 학습-테스트를 다 해봐야 알 수 있지만, 그건 너무 비싸다. 대신 각 클러스터 중심끼리의 코사인 유사도를 평균낸 값을 proxy로 쓴다.
실험해보니 이 값이 실제 transferability와 꽤 잘 맞는다고한다. 직관적으로도 여러 클러스터와 두루 비슷한 군집일수록, 거기서 배운 게 다른 데에도 쓰이기 좋다.
Density
density는 “이 클러스터 안 샘플들이 서로 얼마나 비슷한가”를 뜻한다. Gaussian kernel 평균으로 계산하는데, 값이 크면 비슷한 게 많아 중복이 심하다는 의미다. 이런 군집에서 샘플을 많이 뽑아봤자 같은 데이터만 반복하는 셈이라 효율이 떨어진다.
비중 배분과 샘플링
transferability proxy $S_i$와 density $D_i$를 조합해 각 군집의 비중 $P_i$를 정한다.
$$ P_i = \frac{\exp\!\left( \tfrac{S_i}{\tau D_i} \right)}{ \sum_k \exp\!\left( \tfrac{S_k}{\tau D_k} \right)} $$
여기서 $\tau$는 temperature로, 작게 주면 성능 좋은 군집에 더 몰아주고, 크게 주면 골고루 뽑게 된다.
그 다음, 각 군집 안에서는 MMD greedy로 샘플을 고른다. 같은 맛의 과자가 가득 있는 상자에서, 같은 맛만 여러 개 집지 않고 여러 맛을 섞어 담는 것과 비슷하다. 이렇게 하면 소수의 샘플만으로도 군집 분포를 잘 대표할 수 있다.