조금 오래된.. 작년 초 논문이긴 하지만, 특정 Task 에서 Sota를 달성하기 위해 어떤 방법을 사용했고, 특히 부족한 데이터셋은 어떻게 해결했는지 궁금해서 읽어봤다.
우선 DeepSeekMath는 수학 벤치마크에서 당시 Sota를 달성했다. 두가지 접근법이 있었는데 아주아주 많은 고품질의 데이터셋을 모은것, 그리고 GRPO 이다.
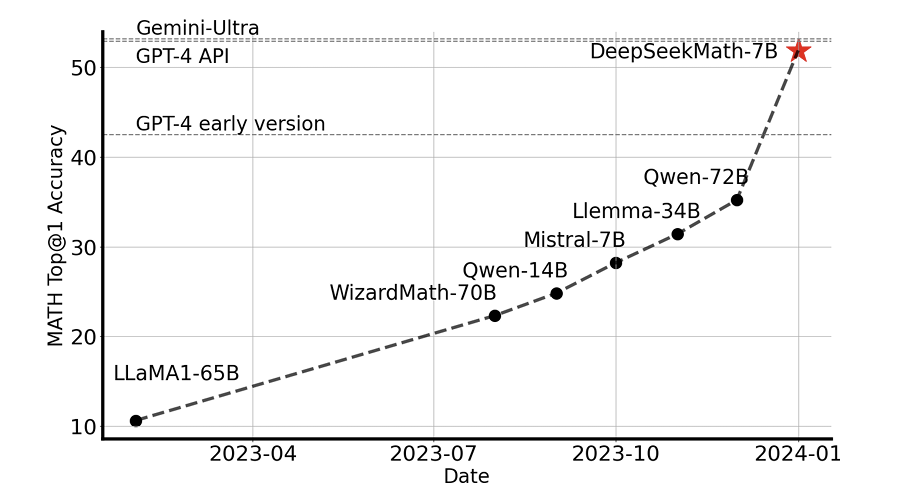
먼저 아주아주 많은 고품질의 데이터셋은 어떻게 모았을까. 알다시피 데이터셋을 만드는건 돈이 많이 든다. GPT를 태워서 데이터셋을 만들다보면 순식간에 몇백이 나가있을거다..
여기서 소개한 데이터셋 모으기 파이프라인의 주요 아이디어는, 데이터를 제작하는게 아니고, 이미 있는 데이터셋을 잘 걸러내서 필요한것들을 잘 뽑아내보자 이다.
Common Crawl이라는 웹에서 그냥 크롤링한 아주 거대한 데이터셋에서, fastText-based classifier 를 사용해서 관련된 데이터셋을 쓕쓕 뽑아내온다. 총 120b math token을 뽑아왔는데, 샘플이 아주아주 크기때문에 규모가 작은 synthetic하거나 real data에 비하면, 대규모의 법칙에 따라, 조금 품질이 떨어져도 데이터가 어마무시하게 많다면 law of magnitude 의 이점을 보게될거다.
그래서 이미 데이터가 충분히 잘 있고, 그 중에서 우리가 high quality데이터를 잘 걸러낼 수 만 있으면 아주 많은 괜찮은 데이터셋을 얻을 수 있을것임을 주장한다.
그럼 여기서 어떻게 high quality 데이터를 쓕쓕 뽑아왔는지를 살펴보자
Data Collection
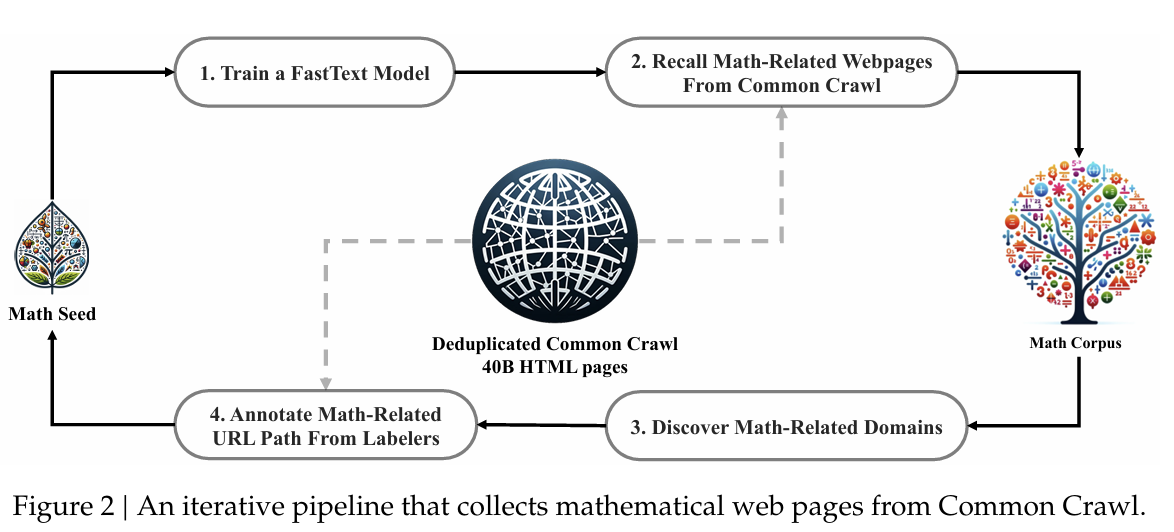
데이터 필터링하는 process는 먼저, Seed Corpus 에서 시작한다.
Seed Corpus란, task에 관련되어있는 작지만 high quality 데이터셋이다. Seed Corpus의 문제점이, 양이 적다는것, 그리고 Diversity가 적다는 문제점이 있다.
예를 들어 DeepSeek Math 는 OpenWebMath를 Seed Corpus로 사용했는데, 이 데이터셋은 high quality 이긴 하지 양이 적고 다양하지는 않다.
그래서 데이터 파이프라인 아이디어는 간단하다. Seed Corpus를 받아서 양이랑 퀄리티 측면에서 늘려야한다.
이걸 하기 위해 Iterative 방법을 쓴다.
Math Seed 에서 시작해서 먼저 FastText라는 Classifier 모델을 학습한다. Seed Corpus(High quality, 적은, relevant한 데이터) 에서 500,000개의 데이터, Common Crawl(웹에서 긁어모은 방대한 데이터)에서 500,000개 데이터를 가져와서 각각 positive, negative로 설정을 한다. 그리고 이 두가지를 split 하기 위한 Classifier(FastText) 모델을 학습한다.
여기서 드는 의문은 이게 제대로 classify가 될까.. 왜냐면 Common Crawl은 너무 다양한 데이터셋이 많은데, 이걸 OpenWeb Math 데이터셋이랑 classifiy하는 부분이 좀 걸린다. 정확하게 classify 가 될지..?
근데 일단 잘 됐다고 치자. 그럼 2단계인 "Recall Math-Related Webpages from Common Crawl" 단계로 넘어간다. 여기서는 Classifier 에서 positive 점수가 높은 상위 40B의 데이터를 가져온다.
그럼 이게 Math Corpus 에 들어간다. 그럼 우선 40B의 데이터로 늘리기가 완료된거다. 근데 이거를 어떻게 120B까지 늘릴까?
Common Crawl은 웹사이트를 크롤링하는 데이터셋이니까, 데이터셋을 보면 다 URL이 있을거다. 도메인이 겹치는 URL들을 URL 이름으로 group하고, 해당 그룹에서 10프로 이상이 Positive로 판정이 됐으면 해당 URL을 전체를 다시 reconsider 하는 형태이다. 그래서 classifier 이 제대로 필터링을 못했어도, 이런식으로 연관된 버려진 데이터셋들을 다시 건져올수 있는거다.
그래서 이렇게 다시 건져진 데이터셋들까지가 4단계 annotation 프로세스로 들어간다. 논문에서는 MANUALLY ANNOTATED 했다고 써져있는데 그럼 하나씩 annotation을 다 단걸까..(그럼 결국 data genertion이잖아!!)
이렇게 Data를 확장을 하고 나면, 이게 다신 Math Seed 에 들어간다. 그리고 이 과정이 계속 반복되면서 데이터가 계속 확장된다. 확장된 Math Seed 로 Classifier 를 다시 학습시키면, Classifier 이 positive로 판별하는 범위는 더 다양해지고~ 이러면서 다양하면서 퀄리티 좋은 데이터를 만들 수 있게 된다.
이런 파이프라인의 가능세계를 생각해보면 일단 두가지 가능성이 있다. Classifier 이 너무 관대해서 데이터를 왕창 왕창 늘려서 결국에 무한대의 웹에 있는 모든 데이터를 가지게 되는 경우, Classifier 이 너무너무 정확해서 4단계에 추가되는 데이터가 없어서 확장하지 않고 converge 하는 경우
전자의 경우 관련이 없는 데이터까지 가져오지 않게 언제 멈춰야하는지에 대한 기준을 세워야하고, 후자의 경우 오히려 좋다.
논문을 읽어보면 이 파이프라인의 가능 세계는 후자에 가까운것 같다. 4번째 iteration을 돌고 나니 추가되는 데이터가 거의 없어서 총 120B의 데이터에 수렴했다고 한다.
Validating the Quality of the DeepSeek Math Corpus
데이터셋이 잘 만들어졌는지? 를 평가한다.
