
<Intro>
T2I 디퓨전 모델은 사용자 텍스트 입력에 따라 고품질 이미지를 생성 가능하며, 최근 몇년간 엄청난 발전을 이뤘다. 하지만 현재의 T2I 모델은 생성된 이미지에서 카메라 시점을 이동시키는 유연성이 부족하다. 사용자가 생성된 이미지에서 카메라를 가까이 이동하거나 멀리 두고 싶어도, T2I 모델은 3D 공간에서 적절한 시점 전환을 구현하지 못한다.
이를 해결하기 위한 기존 접근법과 한계
1. 3D 데이터셋 기반 모델
대규모 3D 데이터셋을 활용하여 단일 이미지에서 새로운 시점을 생성하는 모델을 학습한다. 그치만 object centric하기에, 복잡한 reconstruction을 잘 못한다는 한계가 있음.
2. Warping-and-Inpainting 방법
T2I 모델과 MDE를 결합한 "warping and inpainting" 방식이 제안된다. 입력 이미지에서 depth map을 예측한 뒤, 이를 기반으로 이미지를 새로운 시점으로 왜곡하고, T2I 모델로 왜곡된 이미지의 가려진 영역을 inpainting 하는 방식이다. 이 방식은, depth map의 noise 문제(잘못 예측된 경우), 그리고 왜곡 과정에서의 의미적 정보 손실등의 한계가 있다.
GenWarp의 새로운 접근 방식
GenWarp는 T2I 생성 모델이 "어디를 왜곡하고, 어디를 생성해야 하는지" 학습하도록 설계되었다. 기존의 "warping and inpainting" 단계를 하나로 통합하여, 입력 이미지와 depth map를 기반으로 새로운 시점을 생성한다. Inpainting 대신 self-attention과 cross-view attention을 증강시키는 방식으로 학습을 한다.
<Method>
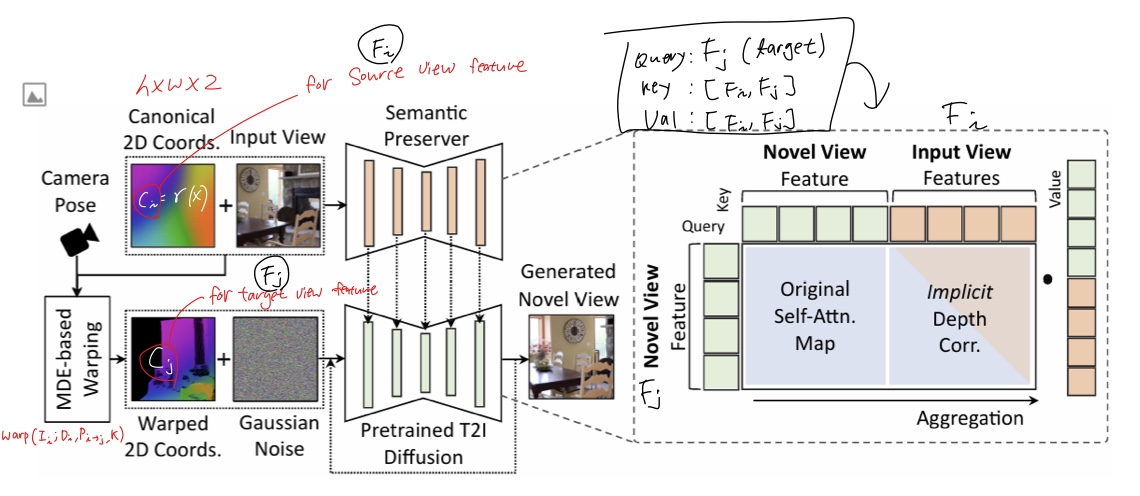
이미지에 해당하는 2D Coordinate 의 embedding, MDE를 통해 추정된 새로운 시점의 좌표 embedding이 입력으로 들어간다. 그러면 Semantic preserver network를 통과해서 입력 이미지의 의미적인 특징이 생성될 것이며, diffusion 모델은 이 semantic feature에 conditioning 해서 novel view의 이미지를 생성한다.
기존의 explicit 한 warping 방식의 한계를 해결하기 위해 Semantic Preserving Generative Warping의 방식을 제안한다.
Diffusion 모델이 warping을 implicit 하게 학습하도록 하는 방식. 이를 위해 attention 방식을 활용하는데, 기존의 Self attention layer에 Cross View attention 이 추가되었다. 입력 시점과 새로운 시점이 cross attention되면서 어디를 warp할지, 어디를 generate할지를 자연스럽게 결정하도록 한다.
그럼 input view 에서 feature들이 어떻게 뽑히고 어떻게 process 되는지 알아보자. 우선 알아야될 함수는 warping 함수이다.
warping 함수는 입력 이미지의 픽셀 좌표를 3D 공간으로 변환하고, 새로운 시점으로 투영하여 왜곡된 좌표를 계산한다. 이 과정은 다음과 같이 표현한다:
$$ C_j = \text{warp}(C_i; D_i, P_{i \to j}, K) $$
여기서:
- \( C_i \): 입력 시점의 좌표 임베딩 (Fourier Features로 변환된 값)
- \( D_i \): 입력 이미지의 깊이 맵 (MDE를 통해 추정)
- \( P_{i \to j} \): 입력 시점에서 새로운 시점으로의 카메라 변환 행렬
- \( K \): 카메라 내재 행렬 (Intrinsic Matrix)
이 함수는 좌표 임베딩 \( C_i \)를 3D 공간으로 변환한 후, 새로운 시점에서 2D 좌표로 project 하는 함수이다. 이 warping 함수를 그대로 Fi Fj를 생성하는데 이용한다.
입력 이미지 \( I_i \)에서 추출된 좌표 임베딩 \( C_i \)는 Semantic Preserver Network를 통해 의미적 특징 \( F_i \)로 변환된다. 이 과정은 다음과 같이 이루어진다:
$$ F_i = \text{SemanticPreserver}(I_i, C_i) $$
여기서 \( C_i \)는 Fourier Features를 사용하여 \( I_i \)의 위치 정보를 포함하는 좌표 임베딩이다. 컨볼루션 레이어를 사용하여 \( C_i \)와 \( I_i \)의 특징을 결합하고, 의미적 정보를 추출한다.
새로운 시점에서의 의미적 특징 \( F_j \)는 Diffusion Model이 입력 이미지의 특징 \( F_i \)와 왜곡된 좌표 임베딩 \( C_j \)를 결합하여 생성한다:
$$ F_j = \text{DiffusionModel}(F_i, C_j) $$
그리고 여기서 제시한 attention 방식도 재밌는데, qkv에 각각 다음의 feature를 넣는다
- Query (\( q \)): $$ q = F_j $$
- Key (\( k \)): $$ k = [F_i, F_j] $$
- Value (\( v \)): $$ v = [F_i, F_j] $$