Intro
General-Purposed Image-Text instruction following assistant를 만들어보자!
즉 이미지와 Question(context)가 주어졌을떄, Answer text를 생성하는 image text instruction model을 만드는게 목표.
이를 위해 LLaVA라는 pre-trained LLM, pretrained visual encoder 구조를, 기존 Data를 reoformation 하는 방식으로 얻은 데이터셋으로 학습했다.
Method
Pretrained text only LLM로는 LLaMA를 사용했고. Pretrained vision encoder로는 ViT-L/14를 사용했음.
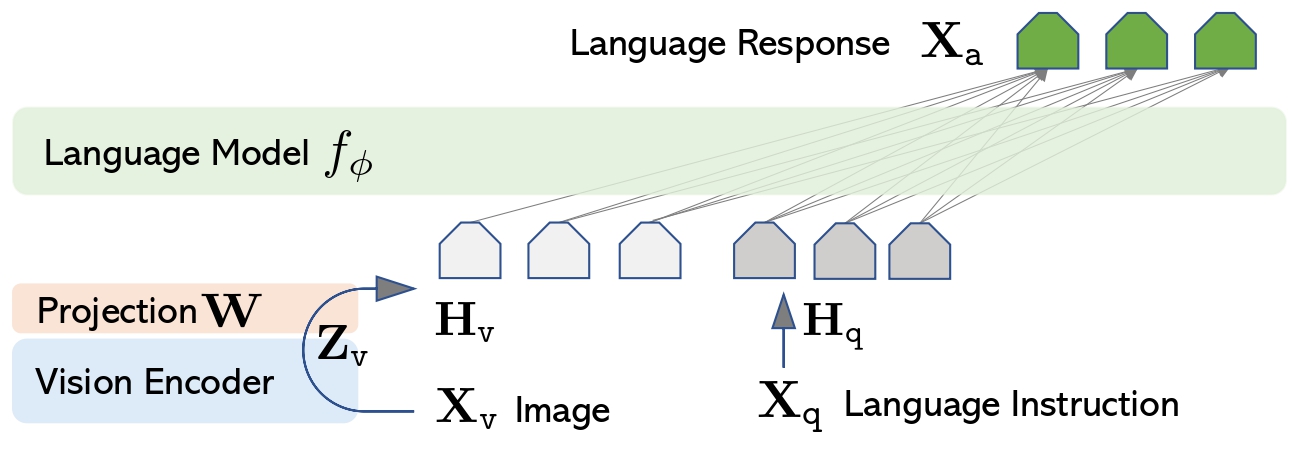
구조는 정말정말 간단하다. 그냥 이미지를 vision encoder 에 태우고 linear layer 하나 달아서 projection 시켜줌으로써 LLM(llama)의 입력이랑 맞춰준것.
그렇게 projected 된 Image feature은 language Instruction이랑 함께 llama에 들어감. -> 이 llama가 일종의 디코더역할로 text, 즉 langage response를 generate 하는 역할을 한다.
사실 모델 구조보다도 더 큰 contribution은 이걸 학습시키기 위한 Data를 어떻게 만들었냐 인거 같다.
일단 기존의 multi modal 데이터셋을 보면, (text, image) paired 데이터셋으로, instruction following, 즉 (Query, Answer) 페어가 필요한 Visual instruction task을 위해 사용하기 적절하지 않았다.
근데 마침, GPT같은 LLM을 통해 query를 바탕으로 높은 수준의 데이터가 생성이 가능해지고 있는 놀라운 시대이다..
그래서 이미지랑, 이미지에 대한 caption이 주어진 상태에서, gpt한테 caption처럼 설명하도록 만드는 query를 만들어보라고 요청.
그래서 이렇게 나온 query까지 instruction following 용도로 사용할 수 있을 것. 즉 쿼리랑, 이미지가 주어졌을떄, 이미지 caption처럼 답변하도록 모델을 훈련시키기 위한 데이터셋을 만들어낼 수 있음.
이 방식을 논문에서는 Naive 한 Data reformation pipeline으로 정의하고 있는데, 이 데이터셋은
Diversity도 부족하고, indepth reasoning도 부족하는 문제가 있었음.
그래서 논문에서는 새로운 data reformation pipeline을 제시한다.
COCO image 데이터셋에 대해 캡션, 이미지, bbox ( Xc, Xv, Xb) 가 주어지면, 사람이 직접 이미지에 대한 질문, 답변 쌍을 생성한다. 그 후 GPT한테, 캡션, bounding box, 사람이 직접 만든(질문, 답변)쌍을 주고, 사람이 직접 만든 질문 답변 쌍을 참고해서 ~~스타일의 user 'question', assistant 'answer'를 만들어보라고 요청.
그래서 {q,a}를 새롭게 만들어낸다.
Training
모델 학습은 Autoregressive 방식으로 이루어진다:
\[ p(X_a | X_v, X_{\text{instruct}}) = \prod_{i=1}^{L} p_\theta (x_i | X_v, X_{\text{instruct}}, x_{<i}, X_{a,<i}) \]
모델은 이미지와 명령어를 기반으로 답변 시퀀스의 각 토큰을 예측하는 방식으로 학습한다.
위에 데이터 생성 부분에서 설명했던거처럼 이미지 \( X_v \)에 대해, conversation data \( (X^1_q, X^1_a, \dots, X^T_q, X^T_a) \)를 생성한다, \( X^t_{\text{instruct}} \)는 다음과 같은 방식으로 구성된다.
\[ X^t_{\text{instruct}} = \begin{cases} \{ [X^1_q, X_v] \text{ 또는 } [X_v, X^1_q] \}, & t = 1 \\ X^t_q, & t > 1 \end{cases} \]
학습방식은 두가지 stage 로 나뉘는데
Stage 1: Pre-training for Feature Alignment

CC3M 데이터셋을 595K개의 image-text pair로 필터링하고,각 샘플은 single turn conversation으로 처리한다. 여기서는 Projection \( W \)만이 학습이 된다. 이를 통해 \( H_v \)가 pretrained 된 LLM의 단어 임베딩과 align 된다.
Stage 2: Fine-tuning End-to-End

그 다음에는 Projection W랑 LLM이 학습이된다.