자연어 문장을 숫자로 표현?
자연어 문장을 표현하려면 단어를 숫자로 표현할 수 있어야함. 그러려면 문장을 단어로 쪼개고, 그 단어를 숫자와 맵핑해야 함
ex)
오늘따라 해피가 너무 보고싶다

단어별로 쪼개기
문장을 단어 단위로 쪼개는 방법은 여러 가지가 있는데. 예를 들어, 형태소 분석기를 이용해 토큰화하거나, 간단하게 공백 단위로 토큰화할 수 있음
Tokenization
예를 들어, 형태소 분석기를 이용해 토큰화하게 된다면 단어 단위로 쪼갤 수 있고, 간단하게 공백 단위로 토큰화할 수 있음
적절한 토큰을 나누고 각 토큰에 대해 숫자를 부여해 dictionary 형태로 놔두면 문장들은 숫자의 나열로 표현할 수 있음
EX
원본 문장: 오늘따라 해피가 너무 보고싶다
Tokenization:
오늘따라, 해피가, 너무, 보고싶다
Index Mapping:
오늘따라: 1, 해피가: 2, 너무: 3, 보고싶다: 4
숫자로 표현된 문장: [1, 2, 3, 4]
근데 인덱스로 매핑하다보면 문제가 있음. 인덱스의 순서가 상관이 없다보니, 인덱스의 거리랑 토큰의 의미적 거리와 상관이 없다는 문제점이 있음. 그래서 나오게 된게 one hot encoding
One hot encoding
각 토큰을 독립적인 차원에 대응시키며, 해당 토큰만 1이고 나머지는 모두 0인 벡터로 표현
원-핫 인코딩 예:
오늘따라: [1, 0, 0, 0]
해피가: [0, 1, 0, 0]
너무: [0, 0, 1, 0]
보고싶다: [0, 0, 0, 1]
그럼 이렇게 표현된 걸 어떻게 다시 문장으로?
Bag of Words
원-핫 인코딩된 벡터들을 합하여 'Bag of Words' 모델을 생성할 수 있음. 이 방법은 단어의 등장 빈도만을 고려하며, 단어의 순서는 무시됨.
Bag of Words 예:
해피가 [0, 1, 0, 0] +
너무 [0, 0, 1, 0] +
너무 [0, 0, 1, 0] +
보고싶다 [0, 0, 0, 1]
결과: 해피가 너무 너무 보고싶다 -> [0, 1, 2, 1]
순서를 무시하다보니까 이것도 문제점이 있음. 그럼 순서가 중요한 애들은 토큰을 묶어버리면 되지않을까? 해서 나온게 n-gram
n-gram
토큰의 순서를 고려하여 정보를 포착하고자 할 때 'n-gram' 모델을 사용함. 이 방법은 인접한 n개의 토큰을 하나의 뭉치로 묶어 처리함.
n-gram 예:
문장: "해피가 너무 너무 보고싶다"
2-gram: ["해피가 너무", "너무 너무", "너무 보고싶다"]
3-gram: ["해피가 너무 너무", "너무 너무 보고싶다"]
그럼 여기서 생각해봐야 하는 건 몇 개의 토큰을 묶을지(즉 n을 무엇으로 설정할지) 왜냐면 n이 너무 크면 사전이 너무 커져버리니까
그리고! 중요한 토큰이 아닌데 빈도수가 높은 경우도 문제.
예를 들어, 조사처럼 의미는 없지만 많이 쓰이는 단어들(영어에서 'a', 'the')등등. 빈도수가 높다고 해서 중요한 것이 아니므로 빈도수 외에 중요도를 고려해야함. 그렇게 해서 나오게 된게 TF-IDF
TF-IDF (Term Frequency-Inverse Document Frequency)
TF-IDF는 단어의 중요도를 평가하는 데 사용되는 통계적 수치.
단순히 단어의 빈도수 뿐만 아니라, 단어가 얼마나 중요한지를 고려하는 것.
TFIDF:
tf(t, d): term frequency, 문장 d에 토큰 t가 나온 횟수
df(t): document frequency, 토큰 t가 나온 문장 수 횟수
idf: inverse document frequency, 단어가 전체 문서 집합에서 얼마나 자주 등장하는지를 반영. 흔하면 작은 값, 희소한 토큰이면 큰 값
N_D: 총 문장 수
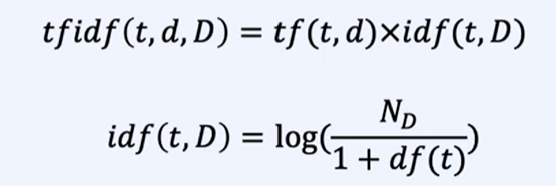
TF-IDF 계산 과정
- TF 계산: 각 단어의 빈도수를 계산
- IDF 계산: 단어가 등장한 문서의 수를 반영하여 IDF를 계산
- TF-IDF 계산: TF 값과 IDF 값을 곱하여 각 단어의 TF-IDF 값을 계산
다음과 같은 문서가 있다고 해보자
- 문서1: "오늘따라 해피가 너무 보고싶다"
- 문서2: "오늘은 정말 해피한 날이다"
- 문서3: "보고싶은 해피가 너무 멀리 있다"
각 단어에 대한 TF-IDF 계산:
TF(오늘따라, 문서1) = 1
TF(해피가, 문서1) = 1
TF(너무, 문서1) = 1
TF(보고싶다, 문서1) = 1
IDF(오늘따라) = log(3/1)
IDF(해피가) = log(3/2)
IDF(너무) = log(3/2)
IDF(보고싶다) = log(3/1)
TF-IDF(오늘따라, 문서1) = TF * IDF = 1 * log(3/1)
TF-IDF(해피가, 문서1) = 1 * log(3/2)
TF-IDF(너무, 문서1) = 1 * log(3/2)
TF-IDF(보고싶다, 문서1) = 1 * log(3/1)
